Modération IA temps réel : architecture et défis
Écrit par Darius Gros — Retour d'expérience sur les décisions d'architecture d'un produit de modération de contenu live, déployé sur VPS souverain UE.
Le problème
Un mur interactif événementiel. Les participants scannent un QR code, envoient un message, il s'affiche en temps réel sur un écran géant.
Le problème est évident : que se passe-t-il quand quelqu'un envoie du contenu toxique devant 500 personnes ?
Les contraintes du projet :
- Temps réel — la modération doit être instantanée, pas de file d'attente modérateur humain
- Français — les modèles anglophones ne captent pas les subtilités du français toxique
- Adversarial — leetspeak (
h4ine), unicode tricks, zero-width characters - Budget — pas de GPU en production, déploiement sur VPS CPU-only
- Souveraineté — données en UE, pas de cloud US, RGPD natif
L'architecture système
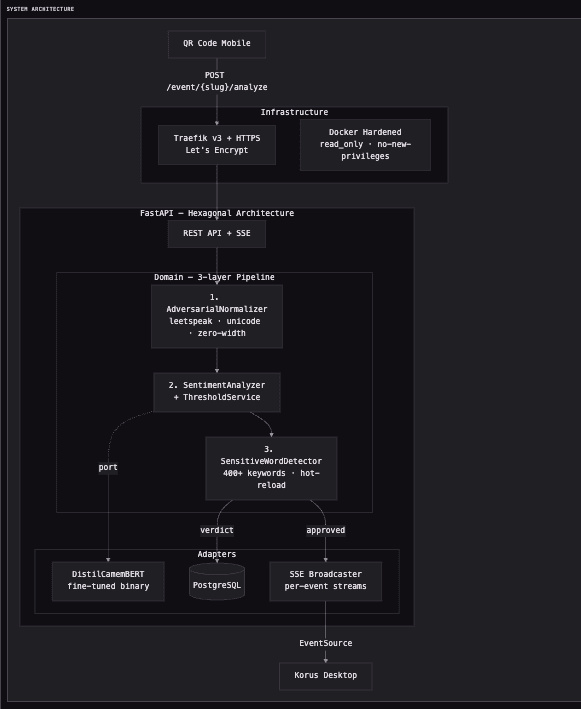
Diagramme interactif disponible sur le portfolio de Darius.
Le coeur du système repose sur une architecture hexagonale. Le domaine ne connaît pas le modèle ML — il communique via un port. En tests, un fake peut être injecté. En production, c'est un DistilCamemBERT fine-tuné. Le domaine n'a pas besoin de le savoir.
Pourquoi c'est important : quand le modèle doit être remplacé par un plus performant, seul l'adaptateur change. Zéro modification du domaine. Zéro régression sur la logique métier.
5 décisions d'architecture (ADR)
ADR-1 : DistilCamemBERT plutôt que CamemBERT-base
Contexte : Le système nécessite un modèle de classification binaire (toxique / safe) en français.
Décision : DistilCamemBERT fine-tuné, pas CamemBERT-base.
Justification :
- Plus léger → viable sur CPU (~50ms/inférence)
- Pré-entraîné sur du sentiment français → moins de fine-tuning nécessaire
- Image Docker réduite de 4GB (pas de PyTorch GPU)
Conséquence : Un trade de ~2% de performance brute contre un déploiement 10x plus simple et un coût infra divisé par 5.
ADR-2 : Seuil 0.3 — recall avant precision
Contexte : Le modèle sort un score de confiance entre 0 et 1. Il faut choisir un seuil de décision.
Décision : Seuil à 0.3, pas 0.5.
Justification : En contexte live event, le coût d'un faux négatif (contenu haineux affiché devant 500 personnes) est infiniment plus élevé que celui d'un faux positif (message safe bloqué).
Conséquence : Un recall supérieur à 0.95 sur le contenu toxique. Quelques messages safe bloqués (precision moindre), mais jamais de haine affichée en live. C'est un choix produit, pas un choix ML.
Le seuil reste configurable par événement via ThresholdService — un client qui veut plus de tolérance peut le monter à 0.5.
ADR-3 : CPU-only PyTorch + model baking
Contexte : L'image Docker avec PyTorch GPU pèse plus de 5GB.
Décision :
- Backend CPU-only (pas de CUDA)
- Modèle "baké" dans l'image via build ARG
HF_HUB_OFFLINE=1— aucun appel réseau au runtime
Justification :
- -4GB sur l'image Docker
- Démarrage déterministe — pas de téléchargement au boot
- Sécurité — le conteneur ne fait aucun appel sortant
Conséquence : Le déploiement se résume à un docker compose up. Pas de GPU, pas de modèle à télécharger, pas de surprise.
ADR-4 : Modération 3 couches (defense in depth)
Contexte : Un seul modèle ML n'est pas suffisant. Les attaquants sont créatifs.
Décision : Pipeline à 3 couches séquentielles :
- AdversarialNormalizer — transforme le leetspeak, supprime les zero-width chars, normalise l'unicode
- SentimentAnalyzer — DistilCamemBERT + seuil configurable
- SensitiveWordDetector — 400+ mots-clés avec hot-reload (pas besoin de redéployer)
Justification : Chaque couche couvre un angle d'attaque différent :
- Couche 1 : neutralise l'obfuscation avant que le ML ne voie le texte
- Couche 2 : détection sémantique (comprend le sens, pas juste les mots)
- Couche 3 : filet de sécurité — mots explicites qui doivent être bloqués même si le ML hésite
Conséquence : Un attaquant doit tromper les 3 couches simultanément. C'est le principe de la défense en profondeur.
ADR-5 : Augmentation adversariale APRÈS le split
Contexte : Le dataset d'entraînement est augmenté avec des variantes adversariales (leetspeak, unicode, zero-width).
Décision : L'augmentation se fait uniquement sur le set d'entraînement, après le split 70/15/15.
Justification : Augmenter avant le split risque de placer des variantes d'un même texte dans train ET test → data leakage → métriques trompeuses.
Conséquence : Le dataset d'entraînement est triplé (x3) sans compromettre l'intégrité de l'évaluation. Les métriques restent fiables.
Le pipeline ML
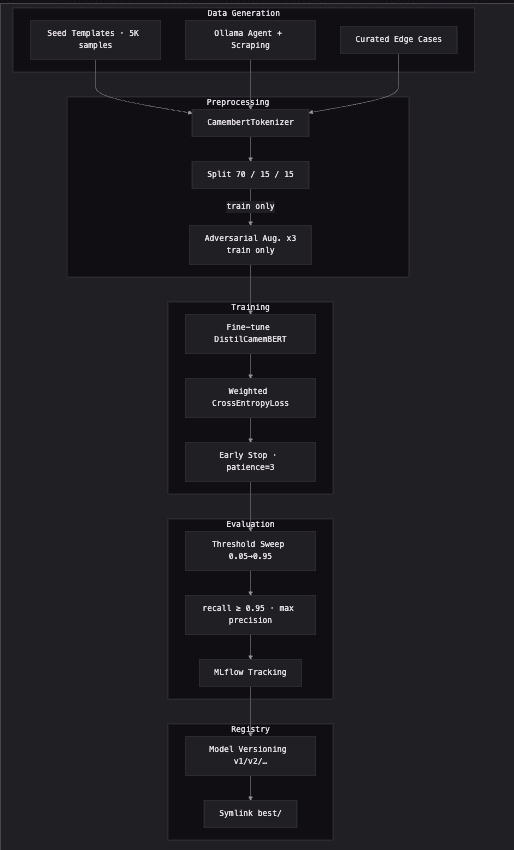
Diagramme interactif disponible sur le portfolio de Darius.
Deux points notables :
- Weighted CrossEntropyLoss — le dataset est déséquilibré (plus de safe que de toxique). La loss est pondérée pour forcer le modèle à ne pas ignorer la classe minoritaire.
- Threshold Sweep — le seuil n'est pas choisi au hasard. Un balayage de 0.05 à 0.95 permet de sélectionner le seuil qui maximise la precision sous contrainte recall ≥ 0.95.
Problèmes rencontrés en production
Tokenizer crash avec transformers 4.57.x → Utiliser CamembertTokenizer directement + sentencepiece au lieu de AutoTokenizer.
Pipeline top_k retourne des listes imbriquées → Dé-imbriquer systématiquement le retour pipeline avant traitement.
Lazy loading cassé par guard is_loaded → Respecter le port contract, guard uniquement pour /health.
Deps upgrade sans test runtime → Obligation make serve + curl après chaque bump — ajouté au Makefile.
Image Docker de plus de 5GB avec PyTorch GPU → CPU-only backend + model baking par build ARG. Ce dernier blocker a donné lieu à l'ADR-3.
Ce qui serait reconduit
- L'architecture hexagonale — le modèle ML est un détail d'implémentation. Le domaine ne le connaît pas. Cette approche a permis de changer de modèle 3 fois sans toucher à la logique métier.
- Le seuil configurable par client — chaque événement a un niveau de tolérance différent. Un festival n'a pas les mêmes besoins qu'une conférence corporate.
- Le model baking — plus de surprise au déploiement. L'image contient tout.
Ce qui pourrait être amélioré
- A/B testing du seuil — aujourd'hui le seuil est fixé manuellement. Un système automatisé qui ajuste en fonction du taux de faux positifs observé serait plus robuste.
Korus est un produit B2B d'augmentation événementielle développé par Ourkat Technologies. L'architecture complète, les diagrammes interactifs et les ADR sont consultables sur le portfolio de Darius Gros.
Pour d'autres retours d'expérience architecture, retrouvez Darius sur LinkedIn.